

Key Takeaways
- Model quality stays high when purpose, evidence, and repeatability stay aligned.
- An evaluation scorecard turns review criteria into consistent scoring and clearer feedback.
- Shared criteria between students and educators will make grading fairer and habits stronger.
You will judge model quality faster and more fairly when you score it against clear criteria, not a gut feel. Formative feedback cycles show measurable gains; one synthesis reported a mean effect size of 0.32. The same pattern shows up in engineering labs, since repeated checks beat one big grade. Consistent evaluation will turn modelling from guesswork into a habit you can defend.
Model quality is not about packing the most blocks into a diagram. Quality means your model will answer the question it claims to answer, with results you can explain and repeat. Students improve faster when evaluation looks like a small test plan with logged evidence. Educators grade with less noise when the same evidence is visible to everyone.
What students mean when they evaluate model quality
Students evaluate model quality when deciding whether a model is fit for its stated purpose. The check includes correctness, clarity, and repeatability, not just a clean plot. A model is high-quality when another person can run it and get the same result. A model is considered low-quality when its results depend on hidden tweaks or missing context.
A microgrid lab model exposes this fast. One student tunes a voltage sag response until the waveform looks right, then forgets to state the source impedance used. A lab partner runs the same file and sees a different sag depth, but cannot reconcile the mismatch. Quality drops because the model’s story is not repeatable.
Good evaluation starts with a plain question: what will this model support, and what will it not support. “Runs without errors” is a low bar for engineering work. A model that runs can still violate units, sign conventions, or energy balance. Evaluation shifts the focus from “did it run” to “did it prove anything.”
The core criteria students use to judge model quality
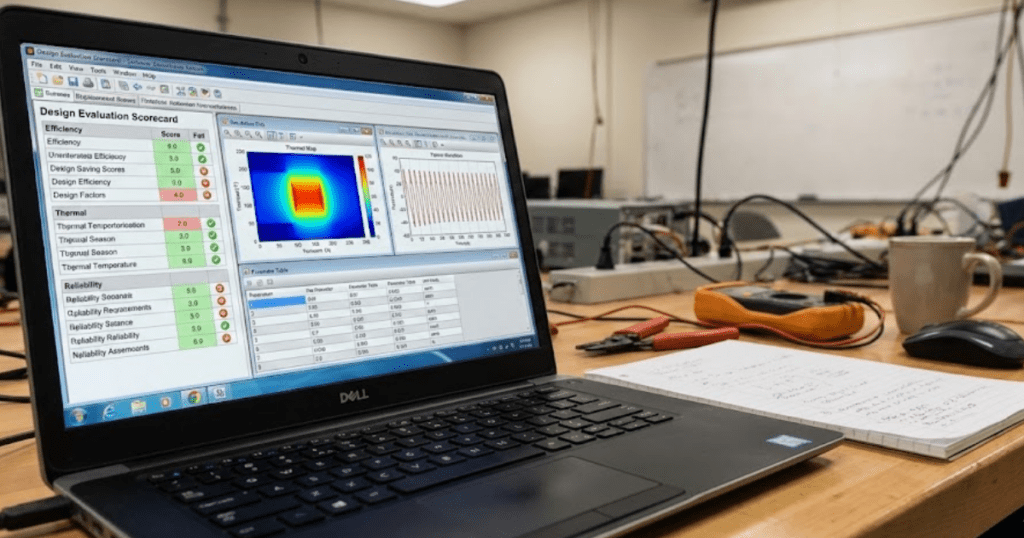
Most student reviews map to a small set of review criteria that work across courses. Accuracy matters, but it must tie to a reference you can defend. Consistency checks matter because they catch mistakes without extra data. Transparency matters because a hidden assumption will break peer review and grading.
An RLC step response assignment makes the criteria concrete. A strong model matches the expected damping ratio, maintains unit consistency, and shows the source of initial conditions. A weak model matches the plot only after random parameter edits, then hides those edits inside subsystems. The same criteria still apply to feeders, converters, and protection logic models.
We trust a model when we can trace each result back to evidence. Accuracy without traceability will not earn trust, since no one can see why the match occurred. Traceability without accuracy also fails, since the model will not answer the task. Quality stays strong when you balance criteria and match the grader’s focus.
“Evaluation shifts the focus from “did it run” to “did it prove anything.”
How students build an evaluation scorecard that stays consistent
An evaluation scorecard turns model review into repeatable scoring. You define criteria, tie each to evidence, and score the same way each time. Consistency beats clever weighting, since graders trust repeatable checks. Self checks speed up when evidence is clear.
Disagreement drops when the scorecard requires evidence. One published study reported an overall inter rater reliability ICC of 0.7 when evaluators scored the same work with a shared rubric. Students can mirror this by anchoring each score level to an artifact, not a feeling.
| Aspect being checked | What strong model quality looks like | What weak model quality looks like |
| Purpose alignment | The model answers a clearly stated question and stays focused on that task from start to finish. | The model includes extra behavior that does not support the stated task or distracts from it. |
| Assumptions visibility | All simplifying assumptions are written down and their impact on results is explained. | Assumptions are implied or hidden, making results hard to interpret or trust. |
| Evidence for correctness | Results are supported by reference checks, sanity tests, or expected physical behavior. | Results rely only on visual agreement or tuning without justification. |
| Repeatability of results | Another person can run the model and reproduce the same outputs using the same inputs. | Results change when someone else runs the model or when files are reopened. |
| Transparency of parameters | Key parameters, units, and initial conditions are easy to locate and understand. | Important values are buried in subsystems or lack units and context. |
| Review readiness | The model includes notes or artifacts that support grading and peer review. | The model requires verbal explanation because supporting evidence is missing. |
Transparent models make scorecards easier to apply, since you can point to equations and parameters. SPS SOFTWARE supports this style when labs need inspectable models for review. Clarity cuts debate and regrading. Feedback gets sharper because each gap maps to one row.
The sequence students follow when reviewing a technical model

A good review order saves time because early checks catch the biggest errors. Start with purpose and scope, then check the structure and run simple sanity tests, then judge the results. The order stops you from tuning a broken model. Notes become easier to follow for peers and educators.
- Confirm the purpose, inputs, and expected outputs
- Check topology and signs against the reference schematic
- Run sanity checks on units, limits, and initial states
- Compare key results to an analytic check or baseline run
- Record tests run and evidence collected
A lab partner reviewing a converter model can apply these steps in minutes. The reviewer confirms the switching frequency and control targets, then checks the power-stage wiring. A no load run should keep current near zero and voltages in range. Only then should the reviewer judge efficiency or waveform shape.
Later tests assume earlier checks are correct. Controller tuning before sensor scaling checks will waste hours and still result in a failing grade. The sequence reduces bias in peer assessment, since everyone follows the same path. Educators grade faster when the student assessment steps align with the grader’s workflow.
How assumptions and scope shape student quality assessments
Assumptions and scope define what “correct” will mean for your model. A model can be excellent inside its scope and useless outside it. Students who write scope clearly avoid unfair criticism, since reviewers know what was intentionally left out. Educators reward clear scope because it shows engineering judgment.
A power electronics task that targets control-loop stability illustrates the trade-off. An averaged converter model will cleanly answer the stability question, while a switching model will bury it under ripple and step-size noise. The averaging assumption is valid when you state frequency separation and explain why ripple is not the metric. Quality rises because the model matches the task.
Scope also changes what tests you should run. An EMT level network study will need checks on time step, solver limits, and numerical stability, while a steady state RMS study will need checks on balance and phasor assumptions. Students lose points when they test the wrong thing, then claim the model is “validated.” Clear scope keeps tests aligned with what the model claims to represent.
Common errors students make when scoring model quality
Students often score models based on output shape rather than evidence. That habit rewards tuned models and punishes models that document their work. Another error is mixing critique of the idea with critique of the implementation. Quality scoring should focus on what the model proves, not what you wish it proved.
A classic failure occurs when a single nominal waveform match ends the review. The model passes the nominal case but fails under a small change, such as a load step or a shift in fault impedance. Another failure shows up when time steps are chosen for speed, which distorts dynamics and hides instabilities. Review criteria that include repeatability and sensitivity checks will catch both issues.
Self assessment also fails when documentation gets skipped because the model is “obvious.” Missing units, initial states, or parameter sources will block grading and peer review. Students also lose points when a value changes without a note, so the final model has no audit trail. A scorecard forces discipline, since each row needs a specific artifact.
“The closing judgment is simple: disciplined evaluation is part of engineering, not extra paperwork.”
How educators align feedback with student assessment criteria

Educators grade student models best when feedback points to the same evidence students used for scoring. Clear criteria reduce arguments about style and focus attention on what the model will support. Alignment also means educators will show what “good” looks like in the same format used for grading. Students learn faster when feedback turns into the next test you should run.
Calibration before grading keeps scores consistent across sections. Two graders score the same sample model, compare notes, and adjust scorecard wording until scores match. Students can mirror this during peer review by swapping models and scoring them independently, then discussing one mismatch at a time. The result is fairer grading and stronger habits.
The closing judgment is simple: disciplined evaluation is part of engineering, not extra paperwork. Students who treat review criteria as a test plan will build models that teach as they run. Educators who align comments with the scorecard will spend less time defending grades and more time coaching. SPS SOFTWARE supports this approach when labs want transparent, inspectable models that make evidence easy to show.




