Key Takeaways
- A useful microgrid simulation starts with a narrow study question that sets scope, fidelity, and outputs before any modelling begins.
- Accurate component ratings, source definitions, and control roles matter more than model size when you build a first-pass microgrid simulator.
- Steady state validation will decide if your disturbance results deserve trust, especially for islanded and grid-connected transitions.
The best microgrid simulation starts with a study question and a model scope you can defend.
Good results come from disciplined setup, not from piling every possible component into your microgrid simulator. Solar and battery storage account for 81% of planned United States utility scale generating capacity additions for 2024, which shows how much new power system work now centres on inverter-based assets that need careful control models. You will get farther, faster, when the model starts with a clear operating question, consistent ratings, and controls matched to the study. That approach gives beginners a workable path and gives experienced engineers a model they can trust.
“You should write one sentence that defines success before you model anything.”
Choose the study question before picking a microgrid simulator
Start with the study question. A microgrid simulator only helps when the model answers a specific operating problem such as voltage support, protection response, fuel use, or islanding stability. That choice sets the needed components, control detail, time step, and output signals before you place a single block.
A campus microgrid used for peak shaving needs a different setup than a remote mining site that must carry load after a utility outage. The first case will focus on dispatch logic, tariff windows, and the point of common coupling. The second will focus on source sharing, frequency control, and black start order. Both are microgrids, but the simulation work is not the same.
You should write one sentence that defines success before you model anything. A good version sounds like this: you need to verify that battery storage and one diesel unit will hold frequency inside limits after feeder separation. That sentence cuts out noise, keeps the model small, and tells you what outputs will matter when you review results.
Match model detail to the behaviour you need
Model detail should match the behaviour you need to see. Steady power sharing, fault current, converter switching, and resynchronization do not belong at the same fidelity level in one first pass model. A simpler model with the right states will give you better answers than a detailed model with the wrong focus.
If your goal is feeder loading and energy balance over an hour, average converter models will work well and will run quickly. If you need switching ripple, semiconductor stress, or fast current loop response, you will need a much smaller time step and more internal states. Many beginner projects stall because the model starts at the most detailed level before the basic control logic has even been checked.
| Study focus | Model detail that usually fits |
|---|---|
| Daily energy scheduling across solar storage and diesel units | An average value model is usually enough because the main question is power balance over minutes or hours. |
| Voltage and frequency recovery after islanding | A dynamic control model with source governors or inverter loops is needed because the transient response sets stability. |
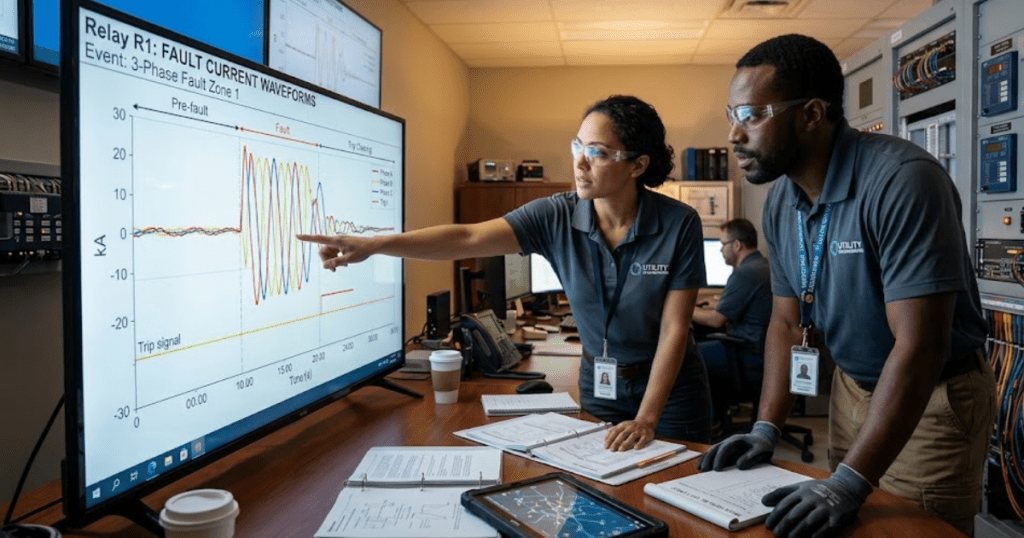
| Protection pickup and fault current contribution | A short-circuit-capable network model is needed because relay timing depends on current magnitude and source impedance. |
| Converter switching stress and waveform quality | A detailed electromagnetic transient model is needed because switching states affect current ripple and harmonics. |
| Resynchronization before reclosing to the utility | A control-focused model is needed because phase angle, slip, and breaker conditions matter more than internal device physics. |
You do not need one perfect model that answers every question. You need the smallest credible model for the first question, then you refine only where the next study needs more detail. That sequencing keeps the work clear and stops the simulator from turning into a large drawing that explains very little.
Build the electrical network from rated component data
Build the network from rated data and a single base set. Feeder voltage, transformer ratios, source impedance, cable lengths, and load power must agree before any controller can behave sensibly. When these values line up, the first power flow check will expose wiring or unit errors early.
A clean starting network often includes one utility source, one feeder, one transformer, several aggregated loads, and each local source tied at the correct bus. A common beginner mistake shows up when a 480 V inverter is connected directly to a 13.8 kV feeder with only a nominal ratio entered somewhere else. The simulation will still run, but every current, voltage, and fault level will be misleading.
This is also where transparent modelling matters. SPS SOFTWARE fits well when you want to inspect each electrical parameter and see how buses, sources, and control ports connect before tuning begins. That kind of visibility helps you catch base mismatches early, which is far more useful than trying to explain odd plots later.
Represent distributed resources with the right control detail
Distributed energy resources should be modelled at the control layer that affects the study. A photovoltaic inverter used for ride through needs different internal detail than a diesel genset used only for dispatch and droop sharing. You will get cleaner results when each resource carries only the states that matter.
A battery unit usually needs a state of charge calculation, active power limits, reactive power control, and one clear operating mode. A diesel generator needs governor response, exciter action, and minimum loading logic. A photovoltaic source often needs irradiance input, dc link behaviour at the right abstraction, and voltage or power factor control. Lumping all three into generic controlled power sources strips away the behaviour that makes microgrids hard.
System planners added 14.3 GW of battery storage to the United States grid in 2024, which underlines why storage control assumptions now shape many distributed resource studies. That matters in practice because storage can switch from energy shifting to frequency support in seconds. If your control model cannot represent that role, the microgrid simulation will miss the asset that often keeps the system stable.
Define the grid connection at the point of common coupling
The grid connection should behave like a defined electrical source, not a vague infinite bus icon. Set short circuit strength, X/R ratio, nominal voltage, breaker logic, and export limits at the point of common coupling. Those settings decide how your microgrid will respond to faults, power swings, and reconnection checks.
A weak feeder and a stiff feeder produce very different voltage behaviour when a battery inverter ramps from 0 to rated power. The same difference appears when a motor load starts or when a fault clears near the site. If the point of common coupling is left as an ideal source with no meaningful impedance, you will hide the exact interactions that make grid-connected studies useful.
You should also define who controls active and reactive power while the utility is present. Some microgrids import a fixed amount and let local generation fill the rest. Others hold zero export or run a voltage schedule at the connection point. Those rules shape controller targets and stop confusion when you compare grid-connected results with islanded results later.
Set islanded control before simulating mode transitions
Islanded operation needs its own control design before you test any transfer event. Voltage and frequency support must shift from the utility side to local grid-forming sources, storage, or generator governors as soon as the breaker opens. If that hierarchy is missing, the simulator will report a crisis you actually created in the setup.
A small industrial microgrid offers a good example. While connected to the utility, a battery inverter can run in power control and simply track a dispatch setpoint. Once the tie breaker opens, that same unit must switch to voltage and frequency regulation, or a diesel unit must take that role immediately. If neither source is assigned that duty, the bus frequency will drift and loads will trip for reasons that have nothing to do with equipment ratings.
Transfer studies also need practical timing. Breaker open delay, controller mode change, load shedding thresholds, and resynchronization checks all matter more than a neat single step event. You’re testing a sequence, not a symbol change, so the model should reflect the sequence the plant will actually use.
Fix scaling errors before tuning any controller
Fix units, bases, and sign conventions before you tune controllers. Most unstable beginner models suffer from kilowatts entered as watts, line-to-line values used as phase values, reversed current polarity, or mismatched per-unit bases. A tuned controller will not repair arithmetic that is already wrong.
The easiest way to catch these issues is to run a short steady state case and inspect every source and load measurement before any disturbance is applied. A battery that appears to charge when your dispatch says discharge is a sign error. A current that looks three times too large often points to a line-to-line and phase voltage mix up. You can save hours if you stop here and correct the scaling first.
- Check that every source rating uses the same apparent power base.
- Confirm voltage entries use the same phase reference across the network.
- Verify positive power flow points in one agreed direction.
- Match controller limits to equipment ratings rather than default values.
- Review initial conditions so storage and generators start from sensible states.
Controller tuning only has value after those checks pass. If you skip them, you will tune compensators around bad data and lock the mistake deeper into the model. That is why experienced engineers spend so much time on setup discipline before they touch gains.
“Microgrid models become useful when you treat them like test benches, build them in a disciplined order, and refuse to trust a plot that the steady state case has not earned.”
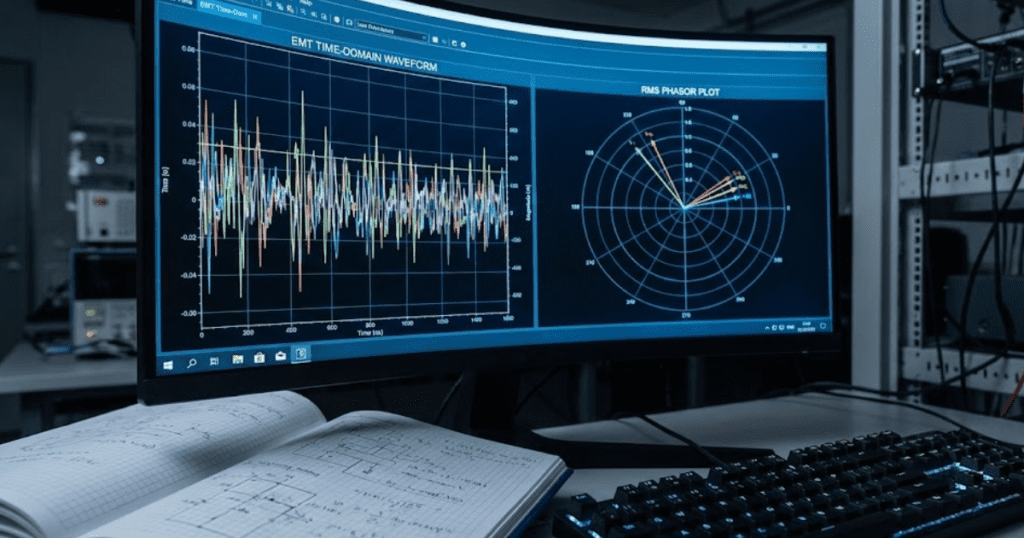
Validate power balance before trusting dynamic results

Trust dynamic results only after the microgrid balances power in steady state. If sources, storage, and loads do not settle to sensible active and reactive power values before a disturbance, every later waveform will mislead you. Validation starts with plain checks, and that discipline saves the most time.
A sound validation pass looks ordinary. You check total generation against total load plus losses, confirm transformer taps and bus voltages, review reactive power sharing, and make sure source current stays within ratings before the event starts. If a campus feeder shows a battery exporting reactive power with no control request, you stop and fix that issue before testing islanding or faults.
This is also where engineering judgment matters more than software confidence. SPS SOFTWARE supports clear, physics-based modelling, but the result still depends on your willingness to verify boring numbers before admiring dramatic waveforms. Microgrid models become useful when you treat them like test benches, build them in a disciplined order, and refuse to trust a plot that the steady state case has not earned.