This guide outlines six simulation checks that help engineers test power factor correction stages for control stability, startup response, and harmonic distortion before hardware testing.
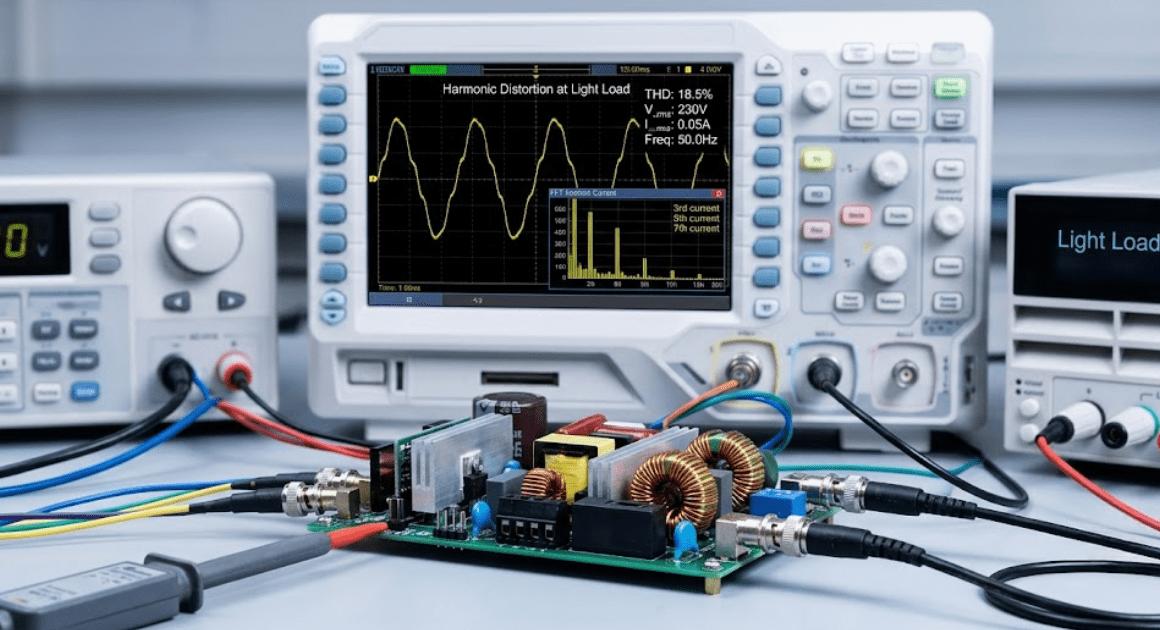


This guide outlines six simulation checks that help engineers test power factor correction stages for control stability, startup response, and harmonic distortion before hardware testing.

A practical guide to choosing EMT simulation software and power system analysis software for transients based on solver visibility, model openness, timestep control, initialization, data access, and workflow fit.

This guide explains how real-time simulation supports power system testing, how it differs from offline studies, and what model and hardware choices matter most for validation.

This piece explains how inverter model fidelity affects renewable grid studies, interconnection reviews, stability analysis, and IEEE 1547 compliance checks.

This guide explains how power electronics simulation software cuts prototype loops, where hardware still matters, and when free tools fit early design work.

A complete guide to hardware in the loop testing for power systems, covering timing, interface design, power electronics control, relay validation, software selection, and common setup errors.

This guide explains what power hardware in the loop testing does, how it differs from controller HIL, and when grid equipment projects need PHIL.

A clear comparison of 6 factors that help engineers, educators, and researchers choose power system simulation software for study accuracy, workflow fit, and long-term use.

