Guide to what a double pulse test measures, how to set up a simulation, and how to estimate switching energy before bench hardware.



Guide to what a double pulse test measures, how to set up a simulation, and how to estimate switching energy before bench hardware.

This guide explains how to run harmonic analysis and power quality analysis in time domain simulation, model nonlinear loads, calculate total harmonic distortion, and check limits at the right buses.
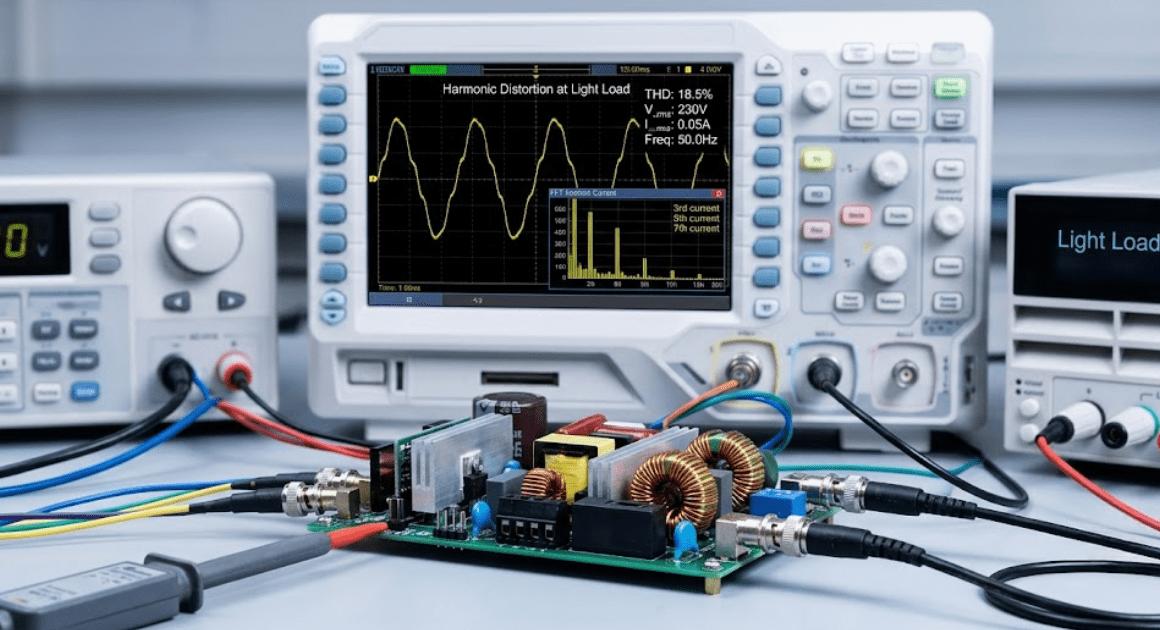
This guide outlines six simulation checks that help engineers test power factor correction stages for control stability, startup response, and harmonic distortion before hardware testing.

Analyzing ferroresonance in transformers and distribution networks explains switching triggers, overvoltage mechanisms, simulation setup, grounding effects, and prevention steps.

This piece explains how to model a battery energy storage system for grid support studies with attention to state of charge limits, inverter controls, plant logic, and fault response.

This guide explains how to validate a power converter prototype through simulation, operating corners, control checks, thermal analysis, fault studies, and a pre hardware checklist before lab testing.

A practical guide to choosing EMT simulation software and power system analysis software for transients based on solver visibility, model openness, timestep control, initialization, data access, and workflow fit.

This piece explains how to model surge arrester behaviour, simulate lightning and switching transients, and verify protection coverage and energy duty across a substation.

